Docker is a containerisation tool, or container runtime, that packages up an app’s source code and dependencies into portable containers that can be run in many different environments. Since a Docker container packages all the app’s dependencies, just distributing the Docker image for that container is sufficient for anyone to run the app anywhere without needing to install anything else. You define everything an app needs inside a manifest file, called a Dockerfile. There are alternative container runtimes like Rocket or LXD.
When you Dockerise an app, you get portability. That’s the main reason people use it. This means you can have a lot of confidence that the app will work on anything that has a Docker daemon running on it, whether it’s your laptop, your co-worker’s laptop, a VM in a data center, a computer in your office, and so on (with some caveats like not being able to run Windows containers on Linux hosts). Docker is especially great for deploying microservices-based applications.
Terms:
Image — a read-only file containing the source code, libs, dependencies and tools for an application. Images are sometimes called snapshots because they capture an application and their environment at some point in development. Images are templates for creating containers
Containers — a running instance of an image that is a runtime environment for an application. You can think of creating a container as just adding a writable layer on top of an image (which is read-only).
Containers just processes, they have a PID, a parent process, can be killed, etc.
A virtual machine virtualises the hardware to run multiple OS instances. A container virtualises an OS to run multiple workloads and multiple containers can share the same OS kernel, making them lightweight
Containers are isolated environments meaning that they have their own filesystem, network, CPU and memory limits, etc.
You can think of a Docker image as a class and a Docker container as an instance of that class
Dockerfile — a file that contains step-by-step instructions for building an image that gets sent to the Docker engine. Dockerfiles document the exact environment as a snapshot. The dockerfile is the starting point — a dockerfile’s commands are executed, creating an image, then a container is built from that image.
Tags — mutable named references to images. They should generally be human-readable
Eg. the Debian image has a tag called ‘buster’, a name for Debian 10. You would pull this specific image with docker pull debian:buster
Container orchestration — the automated running of multiple containers across multiple machines, including their deployment, scaling, load balancing, etc.
You can always run multiple containers manually, but tools like Kubernetes can automate a lot of it for you.
Setting Up Docker
Just install Docker on your system, then enable and start the service. On Arch Linux the setup looks like this:
sudo pacman -S dockersudo systemctl enable dockersudo systemctl start dockerdocker info # Confirms whether the Docker daemon is running.# If you get a 'permission denied' error as a non-root user, then you need to add# $USER to the `docker` group.sudo groupadd dockersudo usermod -aG docker $USER # Add the current user to the docker group.newgrp docker # Log in to the docker group.docker info# Might need to reboot if the above steps are insufficient.
Docker Architecture
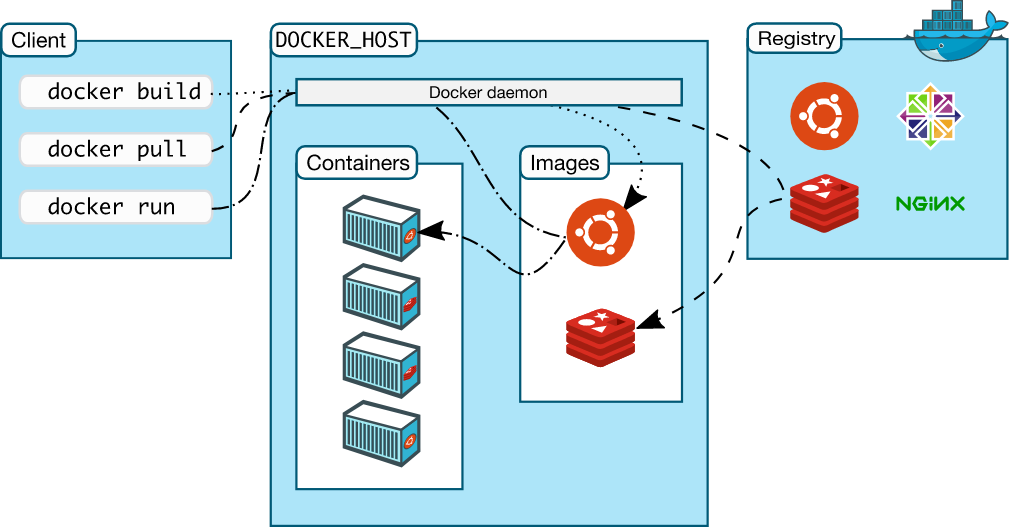
Docker follows a client-server architecture where you have a Docker client that sends requests to a Docker daemon using a REST API. Both the client and daemon may run on the same host or on different machines and communicate over the network.
Docker daemon
A background process listening for API requests. It manages images, containers, and more
Docker client
Issues commands to the Docker daemon. This can be through the CLI, through Docker Desktop, Docker Compose, etc.
Docker registries
Docker registries store images. Docker Hub is the default public registry that images can be pushed to and pulled from (but there exists other registries like GitHub Container Registry and Amazon ECR which has great integrations with ECS for deploying containers)
Using the Docker CLI
The docker CLI needs to talk to the Docker daemon, so make sure that is running on the system first. Usually, the workflow goes like this:
Make an image from the Dockerfile using docker build. All images that have been built or pulled exist as files somewhere under /var/lib/docker/ on Linux. They take up quite a lot of space ☹️ (hundreds of MBs or a few GBs).
If you’re aiming to push the built image to DockerHub, for example, then you should tag the image with a name like <username>/<image_name> using docker build -t <username>/<image_name>.
When you make a new image, the previous image will become a dangling image, ie. one that is not referenced. These will stick around in your filesystem and suck up space unless you remove them.
Run the image to spawn a container process on the system using docker run.
If manually managing the container, then use docker ps to see all the containers that are currently running and use docker stop, docker start, docker rm, etc. to manage them.
# ╠════ Fundamental Commands ════╣# Note: having a .dockerignore file will let you exclude large and unnecessary files from being sent to the daemondocker build <path> # Creating images, where <path> tells Docker where to find the Dockerfile to use. -t <tag> # Assign a human-readable name (tag) to the image we're going to create -f <file> # Path of the Dockerfile. Without this flag, docker build will use look for a file named exactly Dockerfile in the cwddocker run <image> # Running a command in a new container. MAKE SURE THE IMAGE NAME COMES LAST IF YOU USE ARGUMENTS! -d # Run in detached mode, as a background process -p 8080:80 # Exposes a container port by mapping the host's port 8080 to the container's 80, for instance. # -p 8080:80 says "forward any traffic coming to my port 8080 to the container's port 80" --name <containerId> # Giving an ID to the container. Useful when looking at `docker ps` output. If no name is specified, a random one will be generated -v <volName>:<path> # Use the given volume <volName> and mount it to <path> -w <path> # Sets the working directory (which is necessary if you're going to run commands that depend on being on a certain path) --network <networkName> --networkalias=<name> -e key=val # Set an environment variable --env-file <file> # Use a .env file for setting environment variablesdocker stop <containerId> # Stopping a running container. It'll no longer appear in `docker ps`docker start <containerId> # Starting a stopped containerdocker rm <containerId> # Removing a container # Note: to get rid of a container, it must first be stopped with `docker stop <containerId>` and then removed with `docker rm <containerId>` # Container IDs can be found in `docker ps` outputdocker tag <src> <dest> # Create an alias to another image (like a symbolic link). This is useful for `docker push <image>`docker images # `ls` for images -a # Shows intermediary images for each intermediary layer in the build. --filter "dangling=true" # Shows all images that aren't referenced by any other image.docker ps # `ps` for container processes -a # Shows all running and stopped containersdocker logs # Shows container's output log -f # 'follow' the output rather than just printing the output oncedocker exec <containerId> <command> # Runs a command in the given container
DockerHub
Many container runtime systems have a big public repo of container images, called a registry. In Docker’s case, we have DockerHub. There you’ll find images for containers that run, for example, PostgreSQL, NGINX, Node.js, Ubuntu, etc.
To push/pull images to a repo under your DockerHub account, use the commands:
docker push <image> # Pushes an image to Docker Hub (you must have logged in earlier with `docker login -u <username>`docker pull <image> # Downloads an image from Docker Hub (which is the default registry)
Frequent Operations
Some command snippets for things I want to do frequently in my workflow.
# ╠════ Frequent Operations ════╣docker exec -it <containerId> bash # Starts up a Bash shell in your container. Use `sh` if Bash isn't available.docker kill $(docker ps -q) # Stopping all containers.docker rm $(docker ps -a -q) # Removing all containers.docker rmi $(docker images -q) # Removing all images.docker rmi -f $(docker images -f "dangling=true" -q) # Remove all dangling images (images that aren't referenced by any other).
Dockerfile
A Dockerfile is a file that contains a list of sequential commands that can be executed (with docker build) along with the build context to create new Docker images. There are lots of best practices for building images efficiently. Building good images and orchestrating them are complex topics by themselves and require effort and experience.
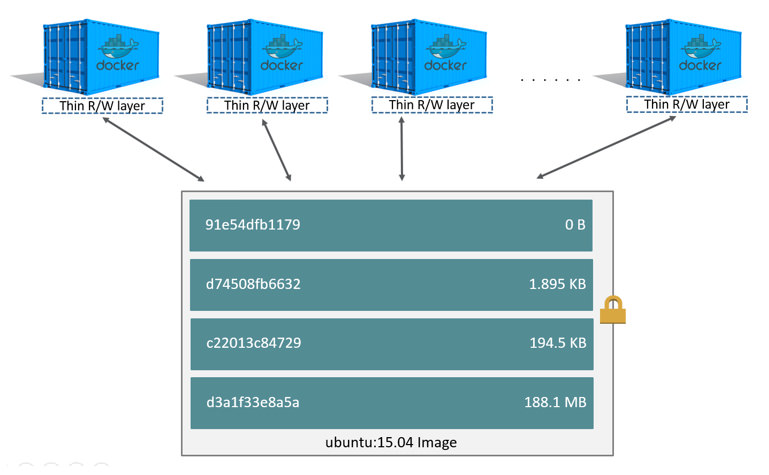
Docker Layers
Docker images consist of read-only layers, each of which corresponds to RUN, COPY and ADD Dockerfile instruction. Each layer stores the set of changes to the filesystem and metadata from the previous layer. Layers exist to be cached and therefore optimise build times. At each instruction in a Dockerfile, the daemon will check its build cache to see if it can skip the current instruction.
An image is basically a diff. It just stores what changes from the image it is based on. Every image always has a base image that it derives from.
An image is a layer. You could use them interchangeably, mostly.
Each layer is a complete image in itself. When you see output like Step 1/4 : ___ while building an image, each of the steps correspond to the building of an intermediary image. Every intermediary image has an ID associated with it that you can spawn containers from.
Step 4/7 : ENV PORT=5678 ---> Running in 967bbecf48fa # The ID of the container that this intermediary image is being built in (I think).Removing intermediate container 967bbecf48fa ---> f8d66c96b15a # This is the ID of the intermediary image
See all intermediary images with docker images -a .
Image layers exist to reuse work and save space.
You can reduce several layers into one with the squash flag --squash in docker build.
When you run an image to spawn a container (with docker run), you are adding a read-writable layer on top of all the underlying read-only layers, called the container layer. All changes such as newly created files are written to this writable container layer.
Generally, writing a simple Dockerfile goes like this:
Choose a base image to start with (eg. Node, Alpine) and specify it with FROM. You must specify a base image. There’s no one ‘correct’ choice, you’re free to experiment with different images (eg. using Debian instead of Alpine).
Ideally, the base image should be well-maintained, slim, and up to date.
Determine the (ideally) minimal set of steps necessary to get your app running after bootstrapping from the base image, then map each of those steps to a Dockerfile instruction. This is kind of a try-and-fail process.
From
Dockerfiles must begin with a FROM instruction. It specifies what base image to start building on top of. You can also specify a tag, otherwise it defaults to the tag with the name: ‘latest’.
FROM <baseImage>[:tag]# In multi-stage builds, you can use AS to give a name to a build and then be able to have one stage # reference another.FROM <baseImage> AS <stageName>
Workdir
Sets what the current working directory is within the container’s filesystem. Creates the folder if it doesn’t exist. You might want to use this before subsequent RUN, CMD, ENTRYPOINT, COPY/ADD instructions.
WORKDIR <path>
As recommended by the official docs, prefer WORKDIR over RUN mkdir -p ....
Run
Runs a shell command. It uses /bin/sh as the default shell in Linux.
RUN ["command", "arg1", "arg2", ...]# Or:RUN command arg1 arg2 ...
Cmd
Like RUN, but it runs a default shell command to start up the application. Unlike RUN, it DOES NOT execute anything when the image is being built!
There can only exist 1 CMD in a Dockerfile. If multiple exist, only the last one is used.
The CMD can be overwritten by docker run if is specifies a command. If you want to guarantee a startup command is always run, then use ENTRYPOINT.
Copies local files (<src>) to the container filesystem (<dest>). It’s recommended to use COPY instead of ADD.
<dest> is either absolute or relative to WORKDIR.
Dockerfile supports file globbing like in bash.
If <src> is a URL, then the file at that URL will be download to the container’s <dest>.
COPY <src> <dest># For multi-stage builds, you use **--from** to source files from a previous stage in the buildCOPY --from=<stageName> <src> <dest>
Add
Almost identical to COPY, but the main difference is that it supports URL sources and other things, making it a bit more unpredictable.
ADD <src> <dest>
Env
Set an environment variable in the container. You can reference this variable in subsequent Dockerfile instructions.
ENV key="value"
Entrypoint
Like CMD, but the command is always run, whereas CMD’s command doesn’t get run if the user supplies their own command. ENTRYPOINT is preferred over CMD when you need a command to always be executed instead of just being the default.
(Not completely sure) Creates a new empty directory at /var/lib/docker/volumes on the host machine (assuming you’re using Linux). The <path> is the container filesystem path whose contents should be linked to the volume directory created on host.
VOLUME <path>
Label
Adds a key-value pair custom metadata field to the image that are viewable with docker inspect. Third party tools around Docker may make use of Labels in your Dockerfiles to organise/manage them.
LABEL maintainer="admin@timz.dev"
Expose
Defines which port to listen on at runtime. Uses TCP by default.
EXPOSE <port>
Example Dockerfile
This is an example Dockerfile for a simple Express server, to be used in a development environment. Sourced from official Docker YouTube.
# You usually start from a base image with `FROM`# This is using `node` as a base image with the tag, 12.16.3, which is the target version.FROM node:12.16.3# Creating a directory. All subsequent commands will use this as the working directoryWORKDIR /code# Setting up an environment variable ENV PORT 80COPY package.json /code/package.json# Installs all dependencies in package.jsonRUN npm installCOPY . /code# The default command to be run when the container is started.# This would run `node src/server.js`CMD [ "node", "src/server.js" ]
Parser Directives
Parser directives are special comments with the form # directive=val
# This defines the location of the Dockerfile syntax that should be used to build the image# Note: this has no effect unless you are using the [BuildKit](https://docs.docker.com/develop/develop-images/build_enhancements/) backend# syntax=docker/dockerfile:1# Tells Docker what characters should be used to escape characters. It defaults to be \# escape=`
Variables
Environment variables defined with ENV can be used in other commands. It’s similar to how bash variables work
FROM ___ENV MY_DIR=/home/tim/ProjectsWORKDIR ${MY_DIR}ADD . $MY_DIR
Dockerfile Optimisation & Best Practices
The goal is to produce lightweight images.
Add unnecessary files to .dockerignore. This prevents sending unnecessary data to the Docker daemon when you run docker build. A good thing to ignore is the node_modules directory.
Pick a lightweight base image. Eg. prefer choosing smaller Linux distributions like Alpine over Ubuntu.
Note: the Alpine Linux distribution is a popular choice for deploying production containers since it’s designed for security, resource efficiency and is a lot smaller than other Linux distributions (eg. Ubuntu 16.04 is around 100MB while Alpine’s image is around 4MB because it only ships with the most essential production tools). Use this to minimise your image sizes. There are also good reasons not to use Alpine, especially for Python apps where you might end up with slower builds, larger images, and a brittle environment!
Merge multiple Dockerfile commands into one. Remember that individual Dockerfile commands correspond to an intermediary image that is built and cached.
# Have the following single command:RUN apk update && apk add curl# Instead of multiple commands:RUN apk updateRUN apk add curl
Start the Dockerfile with steps that are least likely to change in the future. This is because changes to the intermediary images built earlier will invalidate later images.
# Do this:RUN ["yarn", "install"]RUN apk add vim # Rather thanRUN apk add vimRUN ["yarn", "install"]
.dockerignore
When you run docker build, the Docker CLI also sends the build context, which is the set of files located at the specified path or Git repo URL, over to the Docker daemon. Before that, the CLI checks if a .dockerignore is present and ensures that any files declared in there will not be sent to the Docker daemon. It’s purpose is similar to .gitignore
COPY or ADD will also ignore the files in .dockerignore
The syntax is very similar to .gitignore. File globbing is also supported
A typical .dockerignore for a React project might looks like this, for example:
After adding this, you’ll notice that docker build is way faster because node_modules isn’t being sent to the Docker daemon.
Volumes (Shared Filesystems)
A problem: containers can do file manipulation, however any created or updated files are lost when that container process is killed. When a containerised backend server writes to a database, for example, then all the objects in that database are gone after the container process terminates.
With volumes, you can connect paths of a container’s filesystem to paths of the host machine so that files created or updated in that path are also shared with the host. This lets containers persist their filesystem changes.
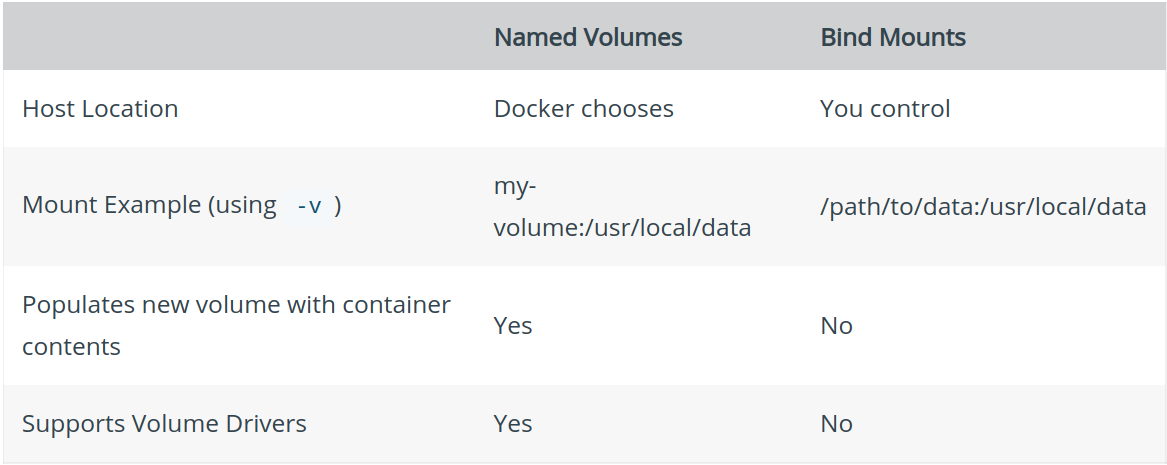
Named Volumes
Docker lets you manage named volumes. It hides away the physical location of where the volume is stored so you, as the programmer, just need to work with the name of the volume.
docker volume create <volumeName> # Creates a new named volumedocker volume inspect <volumeName> # Shows info about the volume such as where its mount point (actual path) is
Bind Mounts
Unlike named volumes, bind mounts let you control exactly where the mount point (the path to the directory of the shared files) is between the host and container.
It can be used where named volumes are used, but being able to set where the mount point is lets us mount our host’s source code into the container to set up hot reloading
In this example which uses nodemon to watch for code changes, you bind mount the directory that you are currently developing in and the container’s working directory so that edits made to the code from the host’s side also affect the code being run in the container’s side.
By bind mounting your project’s directory and the directory where the container is running your app, you are basically syncing the files you’re editing and the files that are in ‘production’ on the container.
Bind mounting is done by passing in a few extra options to your usual docker run command:
docker run -dp 3000:3000 \ -w /app **-v "$(pwd):/app"** \ # Setting the container's cwd to /app and then bind mounting the host side's (your side's) dev directory to the container side's node:12-alpine \ sh -c "yarn install && yarn run dev" # Running a command to kick off the **nodemon** (which is what `yarn run dev` does) after the container starts up
Differences between bind mounts and named volumes:
Multiple Containers
Why Use Multiple Containers?
Although it’s possible to run multiple processes in a single container, in general each container should focus on one thing. If you have a container that runs both a backend server and a database server like MySQL, then it’s generally considered better practice to run both in separate containers because:
API servers, database servers and other components scale differently. Keeping them in separate containers lets you scale each component independently of each other. Eg. you might have a low-traffic but data-intensive app which might mean needing twice as many database containers than backend server containers.
You can rollout a new version to your web server without affecting the database.
For production, it doesn’t make sense to ship the database server with the app.
Each container is less complex.
Container Networking
Containers are isolated processes that have no awareness of other containers running on the same machine. How are they able to talk to each other?
Containers are able to communicate iff they are connected to the same network.
Containers can be connected to non-Docker workloads.
docker network create <networkName> # Creates a new isolated network.docker network ls # List all networks being managed by Dockerdocker run --network <networkName> # Connects a container to the isolated network --network-alias <name> # Gives the container a name that can be used by other containers on the same network to communicate with # The alias to IP mapping is managed by Docker, so you only ever have to work with aliases
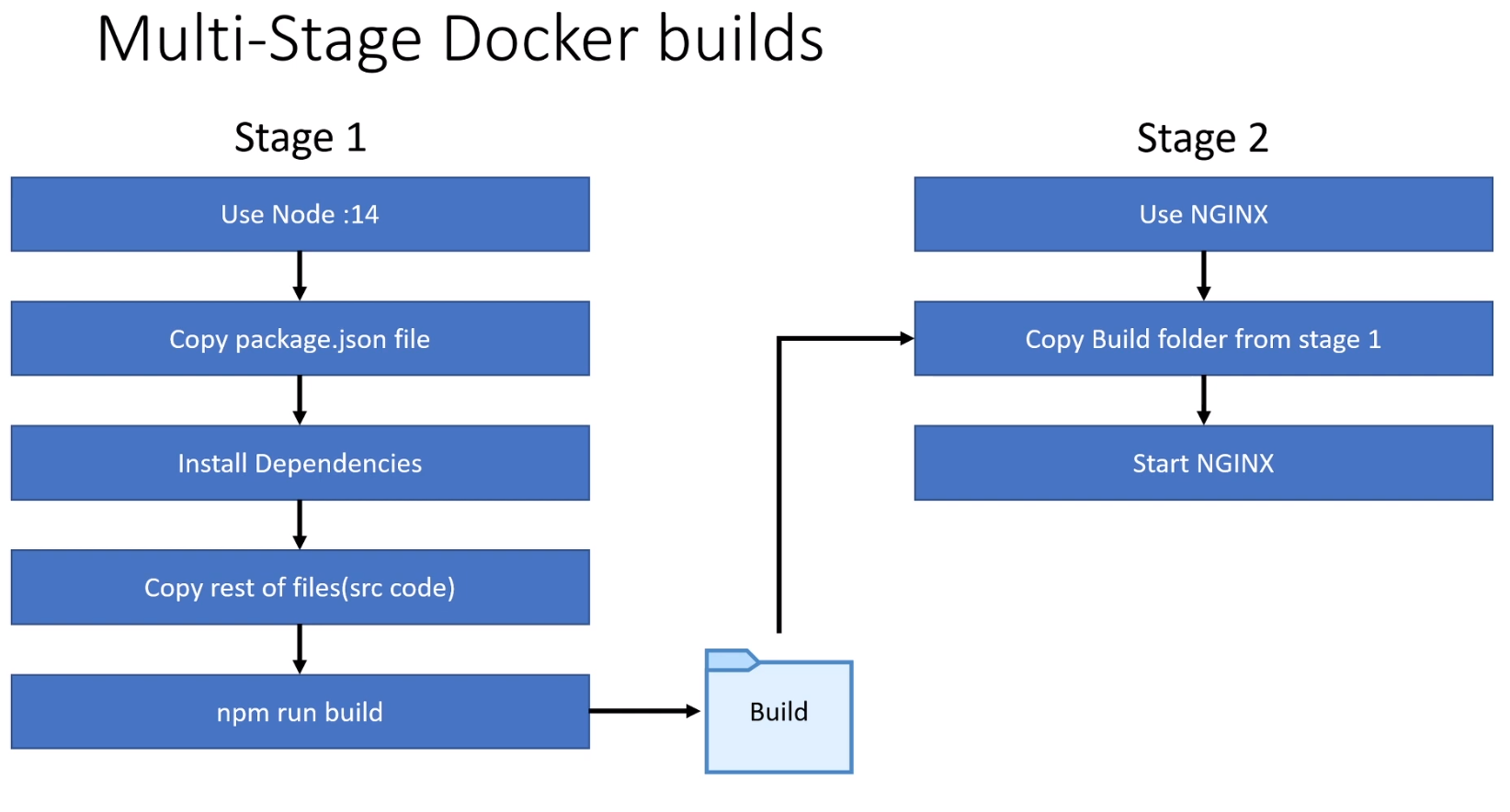
Multi-Stage Builds
Dockerfiles can actually have multiple FROM statements. Every FROM statement marks the beginning of a new build stage. This just means you can create images which derive from multiple bases.
Stages are built in the order they appear in the Dockerfile.
You can copy some output of one layer to the next, across stages. All unneeded artifacts produced from an earlier stage won’t be saved in the final image.
It’s common to run a build in an early stage, then only copy the build results to the next stage (eg. running npm build in 1 stage, then transferring the build files to a directory for NGINX to serve in the next stage).
Example
Suppose you are trying to deploy a React project with NGINX to serve the files resulting from npm build.
# ===== Stage 1 =====# Naming the stage so that it can be referenced by later stages.FROM node:14.18.1 AS build WORKDIR /appCOPY package.json .RUN yarn installCOPY . .# Creating the production-ready files to be served by NGINX in stage 2.RUN ["yarn", "build"] # ===== Stage 2 =====FROM nginx# From Stage 1, copy the build files into the default directory that NGINX serves files from.COPY --from=build /app/build /usr/share/nginx/html
How was this Dockerfile made?
Suppose we’re working on a React project. Here would be a simple Dockerfile to start with:
When you run yarn start, a dev server is spun up which listens to traffic on port 3000 and serves your app. This is not a production-grade server and should not be used in deployment.
For production, we’d actually want to run yarn build to get a bunch of optimised, production-ready files, and then get NGINX to serve them:
We can write a production Dockerfile for the React app by using a first stage that builds the files, and a second stage that spins up an NGINX server to serve those files:
FAQ
You can run an operating system in a container??
Most Docker examples you see will involve using a base container image containing a Linux distribution like the official DockerHub image for Ubuntu.
Docker containers do not contain a complete OS like a virtual machine, it just has a snapshot of the filesystem of a ‘donor’ OS. This idea is powerful enough that you can run a Linux distribution’s entire application layer inside a container, eg. the package manager (apt, pacman, etc.), spawning a shell, etc.
Not every container ‘has’ an operating system. You won’t be able to launch a shell in a container that doesn’t have one.
{kind=link}
{kind=link}

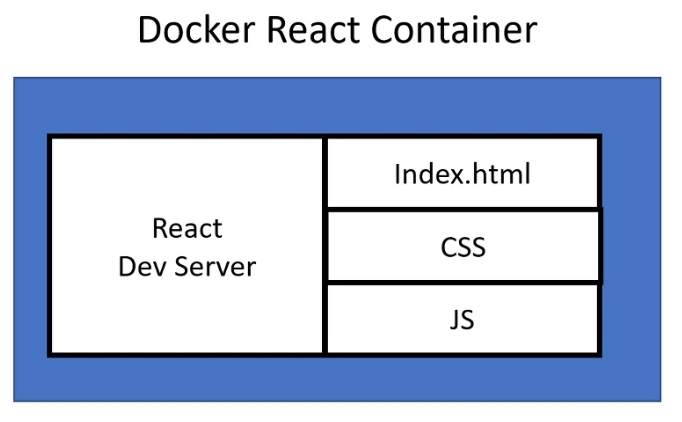 For production, we’d actually want to run
For production, we’d actually want to run  We can write a production Dockerfile for the React app by using a first stage that builds the files, and a second stage that spins up an NGINX server to serve those files:
We can write a production Dockerfile for the React app by using a first stage that builds the files, and a second stage that spins up an NGINX server to serve those files: