{kind=link}
{kind=link}
Always approach the problem with a rational and calm mind. It’s tempting to make knee-jerk solutions that simply exacerbate the problem.
 (source)
(source)
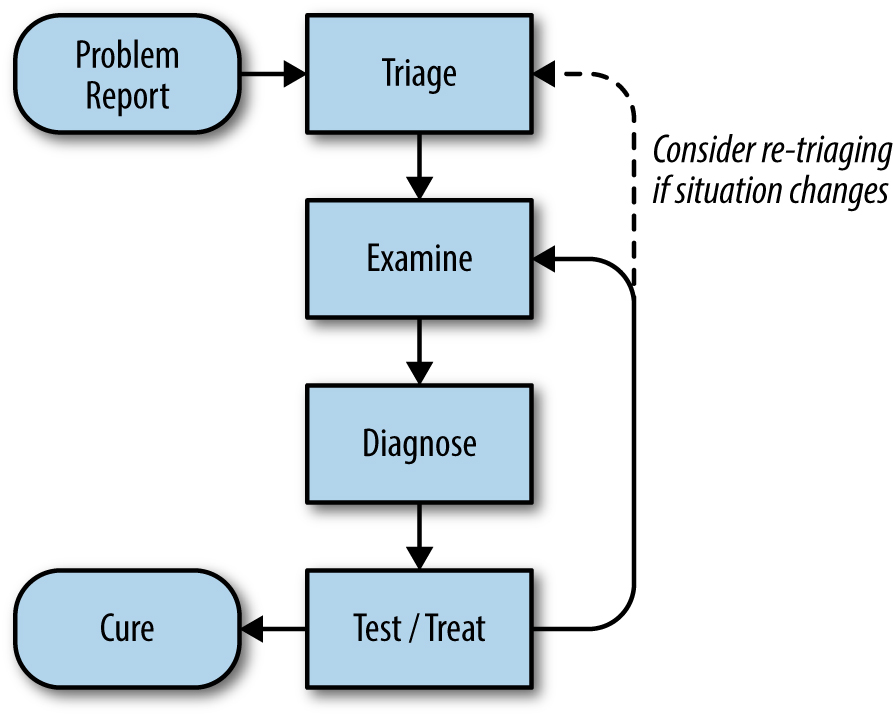
- Know the expected state and the actual state.
- Triage — figure out the scope of the issue.
- Examine — find misbehaving components. Use logs and graphs produced by the monitoring system.
- Diagnose —
- Test/Treat —
Don’t jump to root cause analysis. The first priority is always to “make the system work as well as it can under the circumstances.” I.e. stop the bleeding first.
“Novice pilots are taught that their first responsibility in an emergency is to fly the airplane; troubleshooting is secondary to getting the plane and everyone on it safely onto the ground. This approach is also applicable to computer systems: for example, if a bug is leading to possibly unrecoverable data corruption, freezing the system to prevent further failure may be better than letting this behaviour continue.” — Google SRE book.
This approach to troubleshooting roughly mimics the scientific method:
- Hypothesis — make a conjecture.
- What are the consequences you expect from this hypothesis?
- Seek or produce evidence that confirms or refutes the hypothesis.
- If the hypothesis fails, propose a new one and repeat.
Beware of confusing correlation for causation.
“Some correlated events, say packet loss within a cluster and failed hard drives in the cluster, share common causes — in this case, a power outage, though network failure clearly doesn’t cause the hard drive failures nor vice versa. Even worse, as systems grow in size and complexity and as more metrics are monitored, it’s inevitable that there will be events that happen to correlate well with other events, purely by coincidence.” — Google SRE book.